graph TD; A[r_training] --> B[scripts]; A --> C[data]; A --> D[outputs];
Importation, Organisation et Écriture de Données
Formation R
Bonnes Pratiques d’Organisation de Projet
Lorsque vous démarrez une nouvelle analyse, organisez votre travail en créant un système de dossiers structuré :
📂
r_training📁
scripts/(code)📂
data/(jeux de données)📁
outputs/(résultats comme graphiques, tableaux, etc.)
Note
Utilisez des minuscules et des tirets (-) au lieu d’espaces lors de la dénomination de dossiers, fichiers et objets dans R pour maintenir la cohérence et faciliter la gestion.
Comprendre les Chemins de Dossiers
- Un chemin est une adresse qui indique à un logiciel où trouver un fichier ou dossier sur votre ordinateur.
Deux Types de Chemins :
- Chemin Absolu :
/Users/votrenom/Desktop/r_training - Chemin Relatif :
r_training/scripts
L’Avantage d’Utiliser des Projets
R ne sait pas automatiquement où se trouvent vos fichiers. L’utilisation d’un projet RStudio crée un raccourci qui indique à R où tout trouver, rendant votre flux de travail plus fluide.
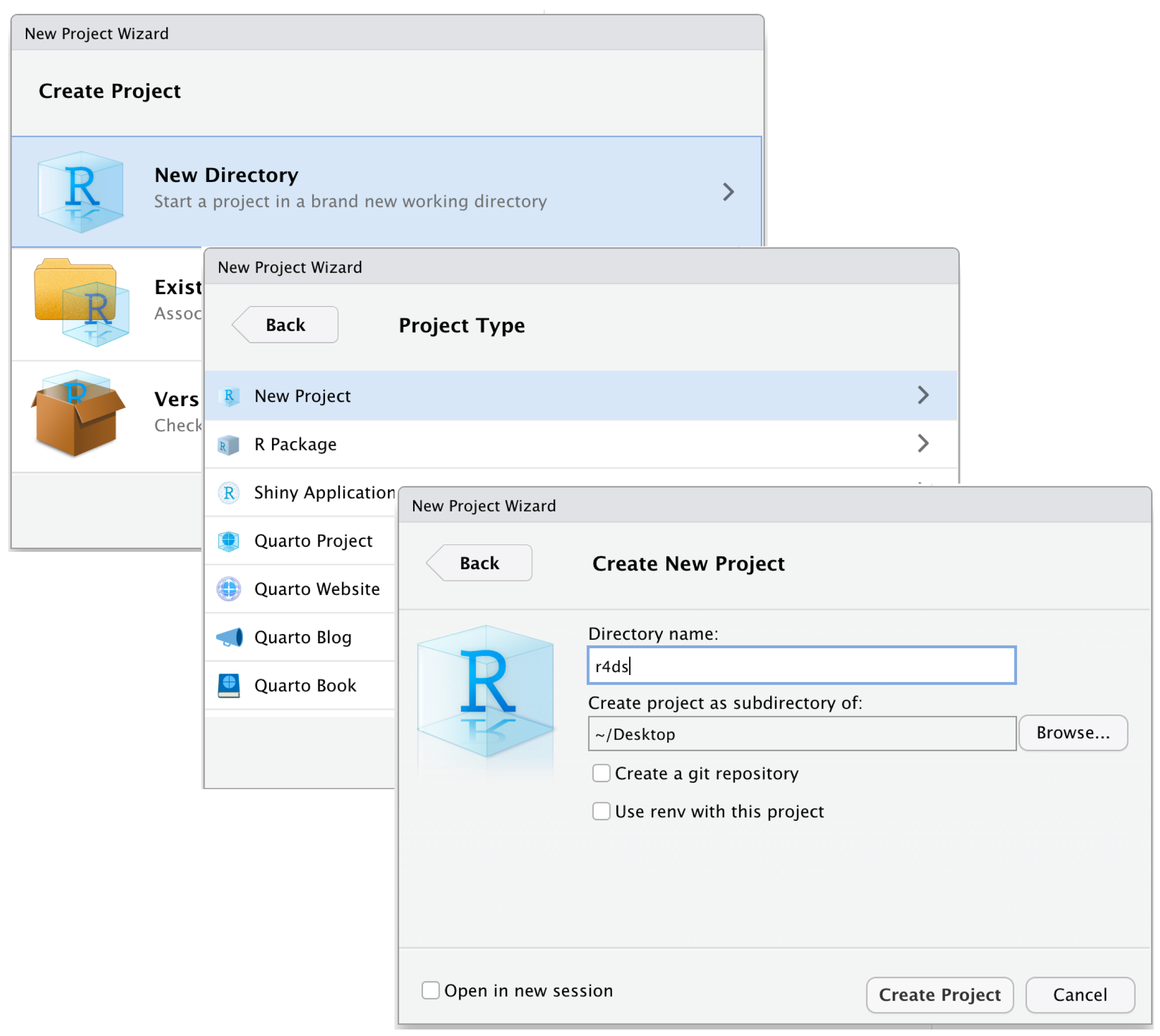
Configuration de Votre Environnement
05:00 Créez un nouveau Dossier nommé
r_trainingCréez un Projet
- Ouvrez RStudio.
- Allez dans File > New Project > Existing Directory.
- Naviguez vers votre dossier
r_traininget cliquez sur Open.
- Cliquez sur Create Project pour terminer.
Ouvrez le Projet (Double-cliquez sur le fichier pour l’ouvrir dans RStudio.)
Exécutez cette commande dans la Console RStudio :
- Suivez les instructions pour décompresser le matériel dans votre dossier de projet.
Vous êtes prêt à commencer ! 🎉
Organiser le Dossier data
graph TD; A[data] --> B[Raw]; A --> C[Intermediate]; A --> D[Final];
Raw
- Données originales, non modifiées.
- Sauvegarde recommandée pour préserver l’intégrité.
Intermediate
- Données formatées, renommées et organisées.
- Prêtes pour un nettoyage supplémentaire.
Final
- Données nettoyées et transformées.
- Prêtes pour graphiques, tableaux et régressions.
Import
Préparer les Données pour R : Concepts Généraux et Bonnes Pratiques
Types de Documents les organisations s’appuient largement sur les tableurs (lire)
Les formats de données courants incluent :
Tableurs (.csv, .xlsx, xls…) : Standard pour données structurées.
DTA (.dta) : Utilisé pour les données de STATA.
Tableurs
CSV est généralement préférable :
Plus facile à importer et traiter.
Plus compatible entre différents systèmes et logiciels et beaucoup plus léger.
Avancé
Le format Apache Arrow est conçu pour gérer efficacement de grands ensembles de données, le rendant adapté à l’analyse de big data. Les fichiers Arrow offrent des opérations de lecture/écriture plus rapides que les formats traditionnels.
Importer des Données dans R
Exercice 1 : Importation de Données
Vous pouvez trouver l’exercice dans le dossier “Exercises/exercise_01_template.R”
10:00 Vos tâches :
Charger les paquets avec
pacmanImporter trois jeux de données :
firm_characteristics.csv(utiliserfread)vat_declarations.dta(utiliserread_dta)
cit_declarations.xlsxfeuille 2 (utiliserread_excel)
- Pour chaque jeu de données :
- Afficher les 5 premières lignes
- Vérifier les noms de colonnes
- Nettoyer les noms avec
janitor::clean_names()
- Bonus : S’assurer que les colonnes d’ID d’entreprise ont le même nom dans tous les jeux de données
Exercice 1 : Solutions
# Charger les paquets
packages <- c("readxl", "dplyr", "tidyverse", "data.table", "here", "haven", "janitor")
if (!require("pacman")) install.packages("pacman")
pacman::p_load(packages, character.only = TRUE, install = TRUE)
# Charger les caractéristiques d'entreprises
dt_firms <- fread(here("Data", "Raw", "firm_characteristics.csv"))
head(dt_firms, 5)
names(dt_firms)
dt_firms <- clean_names(dt_firms)
# Charger les déclarations de TVA
panel_vat <- read_dta(here("Data", "Raw", "vat_declarations.dta"))
head(panel_vat, 5)
names(panel_vat)
# Charger les déclarations d'impôt sur les sociétés
panel_cit <- read_excel(here("Data", "Raw", "cit_declarations.xlsx"), sheet = 2)
head(panel_cit, 5)
names(panel_cit)
# Bonus : Assurer une dénomination cohérente
panel_vat <- rename(panel_vat, firm_id = id_firm) # si nécessaireInspecter les Données
Inspecter Vos Données : Premier Aperçu
- Une fois les données importées, nous voulons d’abord les examiner 👀
# A tibble: 6 × 7
`Taxpayer ID` Name `Tax Filing Year` `Taxable Income` `Tax Paid` Region
<chr> <chr> <dbl> <dbl> <dbl> <chr>
1 TX001 John Doe 2020 89854 8985 North
2 TX001 John Doe 2021 65289 6528 North
3 TX001 John Doe 2022 87053 8705 North
4 TX001 John Doe 2023 58685 5868 North
5 TX002 Jane Smith 2020 97152 9715 South
6 TX002 Jane Smith 2021 62035 6203 South
# ℹ 1 more variable: `Payment Date` <dttm># A tibble: 6 × 7
`Taxpayer ID` Name `Tax Filing Year` `Taxable Income` `Tax Paid` Region
<chr> <chr> <dbl> <dbl> <dbl> <chr>
1 TX009 Olivia King 2022 91276 9127 North
2 TX009 Olivia King 2023 90487 9048 North
3 TX010 Liam Scott 2020 50776 5077 South
4 TX010 Liam Scott 2021 86257 8625 South
5 TX010 Liam Scott 2022 52659 5265 South
6 TX010 Liam Scott 2023 76665 7666 South
# ℹ 1 more variable: `Payment Date` <dttm>Note
Vous remarquerez peut-être que les colonnes Taxpayer ID et Full Name sont entourées d’accents graves. C’est parce qu’elles contiennent des espaces, ce qui enfreint les règles de dénomination standard de R, les rendant non syntaxiques. Pour faire référence à ces variables dans R, vous devez les entourer d’accents graves.
Inspecter Vos Données : Dimensions
- Vérifier les dimensions de vos données :
Inspecter Vos Données : Structure
- Obtenir les noms de colonnes et examiner la structure des données :
[1] "Taxpayer ID" "Name" "Tax Filing Year" "Taxable Income"
[5] "Tax Paid" "Region" "Payment Date" [1] "Taxpayer ID" "Name" "Tax Filing Year" "Taxable Income"
[5] "Tax Paid" "Region" "Payment Date" tibble [40 × 7] (S3: tbl_df/tbl/data.frame)
$ Taxpayer ID : chr [1:40] "TX001" "TX001" "TX001" "TX001" ...
$ Name : chr [1:40] "John Doe" "John Doe" "John Doe" "John Doe" ...
$ Tax Filing Year: num [1:40] 2020 2021 2022 2023 2020 ...
$ Taxable Income : num [1:40] 89854 65289 87053 58685 97152 ...
$ Tax Paid : num [1:40] 8985 6528 8705 5868 9715 ...
$ Region : chr [1:40] "North" "North" "North" "North" ...
$ Payment Date : POSIXct[1:40], format: "2020-01-31" "2021-12-31" ...Inspecter Vos Données : Meilleure Vue de Structure
- Obtenons un meilleur aperçu de la structure et du contenu des données :
Rows: 40
Columns: 7
$ `Taxpayer ID` <chr> "TX001", "TX001", "TX001", "TX001", "TX002", "TX002"…
$ Name <chr> "John Doe", "John Doe", "John Doe", "John Doe", "Jan…
$ `Tax Filing Year` <dbl> 2020, 2021, 2022, 2023, 2020, 2021, 2022, 2023, 2020…
$ `Taxable Income` <dbl> 89854, 65289, 87053, 58685, 97152, 62035, 60378, 876…
$ `Tax Paid` <dbl> 8985, 6528, 8705, 5868, 9715, 6203, 6037, 8768, 9368…
$ Region <chr> "North", "North", "North", "North", "South", "South"…
$ `Payment Date` <dttm> 2020-01-31, 2021-12-31, 2022-01-31, 2023-04-30, 202…Astuce
glimpse() est comme str() mais plus lisible ! Il montre les types de données, les premières valeurs, et s’adapte bien à votre console.
Inspecter Vos Données : Statistiques Résumées
- Générer des statistiques résumées pour toutes les colonnes :
Taxpayer ID Name Tax Filing Year Taxable Income
Length:40 Length:40 Min. :2020 Min. :50438
Class :character Class :character 1st Qu.:2021 1st Qu.:58748
Mode :character Mode :character Median :2022 Median :78590
Mean :2022 Mean :75504
3rd Qu.:2022 3rd Qu.:90287
Max. :2023 Max. :98140
Tax Paid Region Payment Date
Min. :5043 Length:40 Min. :2020-01-31 00:00:00
1st Qu.:5874 Class :character 1st Qu.:2021-04-23 06:00:00
Median :7858 Mode :character Median :2022-01-15 12:00:00
Mean :7550 Mean :2022-01-02 09:00:00
3rd Qu.:9028 3rd Qu.:2023-01-07 18:00:00
Max. :9814 Max. :2023-11-30 00:00:00 Astuce
summary() est incroyablement utile ! Pour les variables numériques, il montre min, max, moyenne, médiane et quartiles. Pour les variables caractères, il montre longueur et classe.
Nettoyer les Noms de Colonnes
- Maintenant, nous allons nous assurer que nos noms de variables suivent la convention snake_case 😎
- Option 1 : Renommer les colonnes manuellement :
- Option 2 : Convertir automatiquement tous les noms de colonnes en snake_case avec janitor :
[1] "taxpayer_id" "name" "tax_filing_year" "taxable_income"
[5] "tax_paid" "region" "payment_date" Exercice 2 : Inspecter les Données
Vous pouvez trouver l’exercice dans le dossier “Exercises/exercise_02_template.R”
10:00 Vos tâches :
En utilisant les trois jeux de données que vous avez importés dans l’Exercice 1 :
- Pour
dt_firms:
- Vérifier les dimensions (lignes et colonnes)
- Utiliser
glimpse()pour examiner la structure - Générer des statistiques résumées
- Pour
panel_vat:
- Afficher les 10 premières lignes
- Vérifier le nombre d’entreprises uniques
- Trouver les noms de colonnes
- Pour
panel_cit:
- Afficher les 5 dernières lignes
- Vérifier s’il y a des valeurs manquantes en utilisant
summary()
Exercice 2 : Solutions
Écrire des Données dans R
Écrire au Format .csv est (Presque) Toujours un Bon Choix
Pour la plupart des cas, écrire des données au format .csv est une option fiable et largement compatible.
Je recommande d’utiliser la fonction
fwritedu paquetdata.tablepour sa rapidité et son efficacité.
- Ci-dessous, nous sauvegardons divers jeux de données dans le dossier Intermediate en utilisant fwrite :
# Écrire les Données TVA
fwrite(panel_vat, here("quarto_files", "Solutions", "Data", "Intermediate", "panel_vat.csv"))
# Écrire les Déclarations d'Impôt sur les Sociétés
fwrite(panel_cit, here("quarto_files", "Solutions", "Data", "Intermediate", "panel_cit.csv"))
# Écrire les Caractéristiques d'Entreprises
fwrite(dt_firms, here("quarto_files", "Solutions", "Data", "Intermediate", "dt_firms.csv"))Il y a d’autres options pour écrire des données
Écrire des Fichiers .rds (Pour Objets R)
Le format .rds est spécifiquement conçu pour sauvegarder des objets R. Il est utile pour sauvegarder des résultats intermédiaires, objets ou données.
Nous explorerons ce format plus en détail plus tard, mais voici un exemple rapide :
- Écrire des Fichiers .xlsx (Pour Compatibilité Excel) : Pour sauvegarder des données au format Excel (.xlsx), utilisez le paquet writexl. Il est léger et ne nécessite pas de dépendances externes.
- Écrire des Fichiers .parquet (Pour Grands Jeux de Données) : Le format .parquet est un format de stockage en colonnes très efficace pour la lecture et l’écriture de grands jeux de données (généralement >1GB).
Pour Résumer
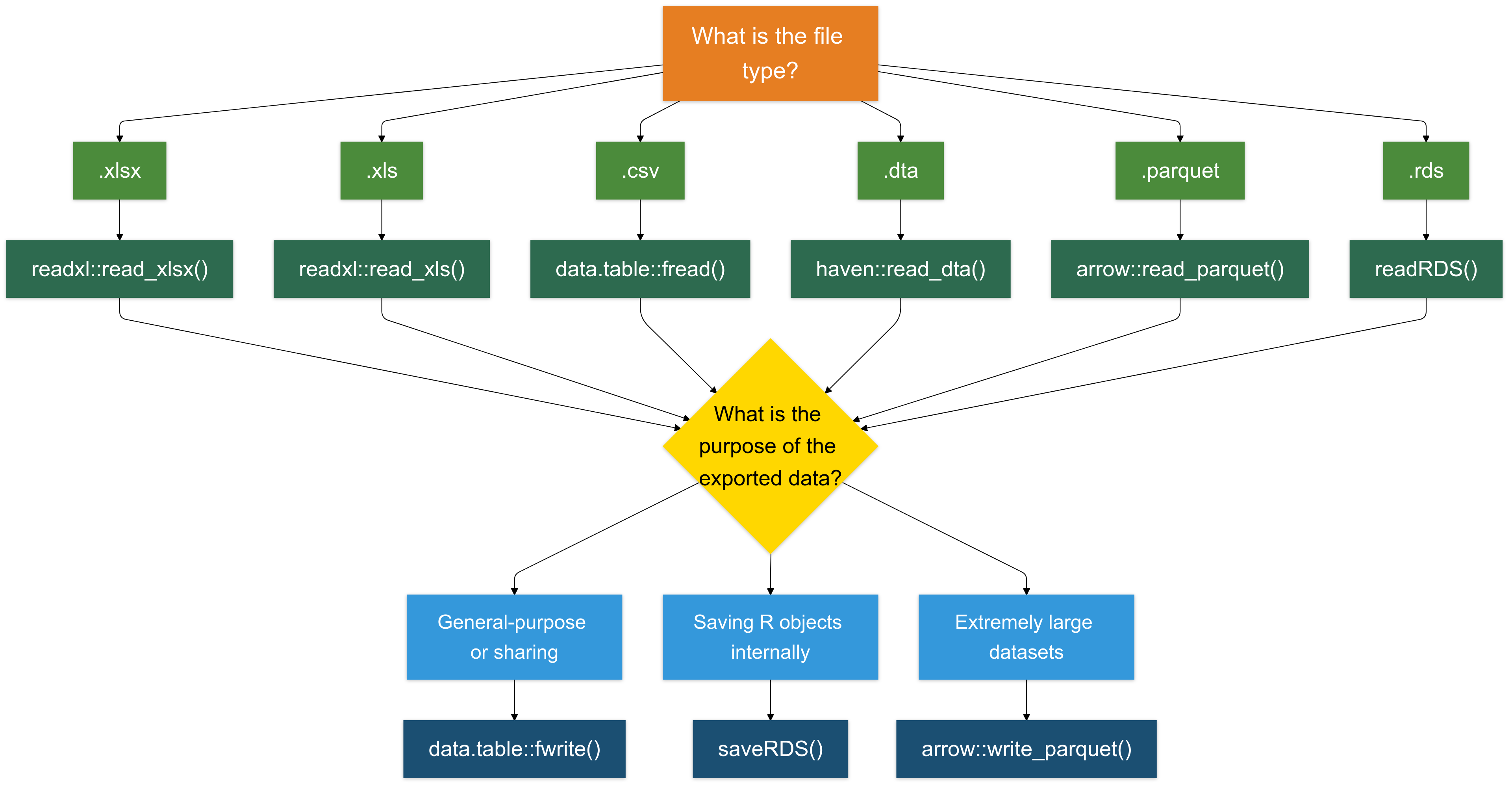
Exercice 3 : Écrire des Données Nettoyées
Vous pouvez trouver l’exercice dans le dossier “Exercises/exercise_03_template.R”
05:00 Vos tâches :
Sauvegarder les trois jeux de données nettoyés dans différents formats :
Caractéristiques d’entreprises → CSV
Sauvegarder commedata/intermediate/firms_clean.csven utilisantfwrite()Déclarations de TVA → RDS
Sauvegarder commedata/intermediate/vat_clean.rdsen utilisantsaveRDS()Déclarations d’impôt sur les sociétés → Parquet
Sauvegarder commedata/intermediate/cit_clean.parqueten utilisantwrite_parquet()Bonus : Pourquoi avons-nous choisi différents formats pour chaque jeu de données ?
Exercice 3 : Solutions
# Charger les paquets requis
library(data.table)
library(arrow)
library(here)
# Sauvegarder les caractéristiques d'entreprises en CSV
fwrite(dt_firms, here("data", "intermediate", "firms_clean.csv"))
# Sauvegarder les déclarations de TVA en RDS
saveRDS(panel_vat, here("data", "intermediate", "vat_clean.rds"))
# Sauvegarder les déclarations d'impôt sur les sociétés en Parquet
write_parquet(panel_cit, here("data", "intermediate", "cit_clean.parquet"))
# Réponse Bonus :
# dt_firms (CSV) : Données de référence, lisibles par l'humain, partagées entre départements
# panel_vat (RDS) : Préserve les types de données R, chargement plus rapide dans les workflows R
# panel_cit (Parquet) : Stockage en colonnes efficace pour grands jeux de données de panelBonus : Connecter R aux Bases de Données
- Pourquoi Se Connecter aux Bases de Données ?
- Les données sont souvent stockées dans des bases de données centralisées pour une sécurité, accessibilité et gestion améliorées.
- Les flux de travail traditionnels peuvent impliquer de soumettre des demandes de données aux équipes informatiques, causant des retards et une flexibilité limitée pour les analystes.
- La Puissance de
Rpour l’Accès aux Bases de Données
- En utilisant
R, vous pouvez : - Interroger les données directement et en temps réel.
- Importer de grands jeux de données de manière transparente dans votre environnement
R.
Avertissement
Cependant, je suggère d’extraire les données en utilisant votre interface SQL puis de travailler avec les données extraites dans R.
Exemple : connexion à une base de données
# Charger les Paquets
library(DBI) # ce paquet est toujours nécessaire
library(RMariaDB) # il y a des paquets pour chaque type de base de données (ex. MySQL, PostgreSQL, etc.)
# Établir une connexion à la base de données
con <- dbConnect(
MariaDB(),
host = "database.server.com",
user = "your_username",
password = "your_password",
dbname = "tax_database"
)
# Interroger la base de données
tax_data <- dbGetQuery(con, "SELECT * FROM vat_declarations WHERE year = 2023")
# Se déconnecter quand terminé
dbDisconnect(con)