Transformation de Données et Jointures
Formation en R
Introduction
Le Défi
Votre directeur entre :
“Nous devons identifier les 5 principales entreprises avec les plus grands écarts de TVA dans le secteur du commerce de détail. Divisez-les par taille d’entreprise—petite, moyenne et grande—sur la base du revenu imposable annuel des données d’impôt sur les sociétés. Pouvez-vous avoir cela prêt pour demain ?”
🤔 Vous pensez :
- Écart de TVA = TVA attendue moins TVA réellement payée
- J’ai des données de TVA trimestrielles dans des colonnes séparées
- Le revenu imposable vient des déclarations d’impôt sur les sociétés (fichier différent)
- Les caractéristiques de l’entreprise (industrie) sont dans un autre fichier
- Je dois joindre les trois jeux de données !
Ce module vous enseigne exactement comment résoudre ce problème.
Feuille de Route d’Aujourd’hui
- Comprendre les principes des données tidy
- Transformer les données entre formats large et long
- Joindre plusieurs jeux de données
- Valider que vos jointures ont fonctionné correctement
- Construire un jeu de données complet prêt pour l’analyse
Résoudre le Défi : L’Approche
Quelles données avons-nous ?
- Déclarations de TVA trimestrielles (format large : colonnes T1, T2, T3, T4)
- Déclarations annuelles d’impôt sur les sociétés (contient le revenu imposable)
- Registre des entreprises (industrie, caractéristiques de l’entreprise)
Que devons-nous faire ?
- Transformer : Convertir la TVA trimestrielle du format large au format long
- Calculer : Totaux annuels de TVA par entreprise
- Joindre : Combiner TVA avec impôt sur les sociétés pour obtenir le revenu imposable
- Catégoriser : Définir la taille de l’entreprise basée sur les tranches de revenu imposable
- Joindre : Ajouter les caractéristiques d’entreprise (industrie)
- Filtrer et Classer : Sélectionner le secteur du commerce de détail, trouver le top 5 par catégorie de taille
Question clé : Comment passer de jeux de données désordonnés et séparés à un tableau propre d’analyse ?
Réponse : En maîtrisant la transformation et les jointures !
Données Tidy
Données Administratives Fiscales Tidy
Que sont les Données Tidy ?
Les données tidy organisent les données administratives fiscales dans un format cohérent et prêt pour l’analyse :
- Chaque variable est une colonne ; chaque colonne est une variable.
- Chaque observation est une ligne ; chaque ligne est une observation.
- Chaque valeur est une cellule ; chaque cellule est une seule valeur.
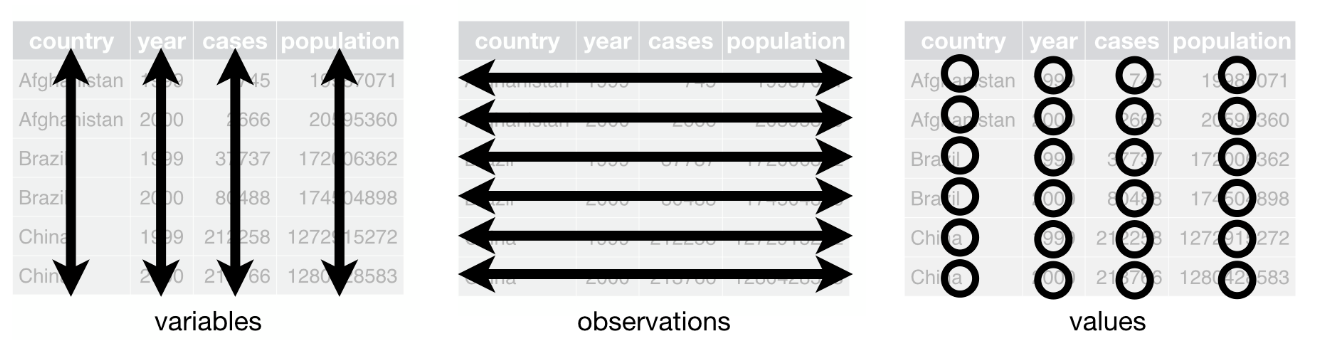
Regardons Cet Ensemble de Données
| ID Contribuable | Type Impôt | 2021 T1 | 2021 T2 | 2021 T3 | 2021 T4 |
|---|---|---|---|---|---|
| 101 | Impôt Revenu | 500 | 600 | 450 | 700 |
| 102 | TVA | 300 | 400 | 350 | 500 |
Quel est le problème avec cet ensemble de données ?
Problèmes :
- L’information de trimestre (T1, T2, T3, T4) est répartie dans les noms de colonnes, pas stockée comme données
- Chaque ligne contient plusieurs observations (données de 4 trimestres)
- Difficile de filtrer par trimestres spécifiques ou de tracer les tendances dans le temps
Quelles sont les variables ?
ID Contribuable, Type Impôt, Trimestre, Montant Paiement.
Qu’est-ce qui constitue une seule observation dans cet ensemble de données ?
Une observation est un paiement d’impôt spécifique pour un contribuable pendant un trimestre particulier.
Le Rendre Tidy
Comment transformeriez-vous l’ensemble de données pour respecter les trois caractéristiques tidy ?
- Chaque variable est une colonne ; chaque colonne est une variable.
- Chaque observation est une ligne ; chaque ligne est une observation.
- Chaque valeur est une cellule ; chaque cellule est une seule valeur.
Version Tidy
| ID Contribuable | Type Impôt | Trimestre | Montant Paiement |
|---|---|---|---|
| 101 | Impôt Revenu | 2021 T1 | 500 |
| 101 | Impôt Revenu | 2021 T2 | 600 |
| 101 | Impôt Revenu | 2021 T3 | 450 |
| 101 | Impôt Revenu | 2021 T4 | 700 |
| 102 | TVA | 2021 T1 | 300 |
| 102 | TVA | 2021 T2 | 400 |
| 102 | TVA | 2021 T3 | 350 |
| 102 | TVA | 2021 T4 | 500 |
Pourquoi Cela Importe-t-il ?
Les données tidy facilitent l’analyse :
- Calculer des statistiques par groupe (ex., paiement moyen par trimestre)
- Créer des visualisations avec ggplot2
- Appliquer des fonctions de manière cohérente à travers les observations
- Joindre des jeux de données sans confusion
L’Objectif
La majeure partie de notre travail implique de transformer des données désordonnées en données tidy, puis de les analyser.
Partie 1 : Comprendre la Structure des Données
Unité d’Observation vs. Unité d’Analyse
Unité d’Observation
Ce que représente chaque ligne dans vos données brutes
- Déclaration de TVA entreprise-trimestre
- Déclaration d’impôt sur les sociétés entreprise-année
- Transaction individuelle
Unité d’Analyse
Ce dont vous avez besoin pour votre analyse
- Taux de conformité entreprise-année
- Tendances au niveau de l’industrie
- Écart fiscal agrégé
Exemple : Vous avez des observations entreprise-trimestre mais besoin d’analyse entreprise-année
- Observations : FIRM_001 a 4 lignes (T1, T2, T3, T4 de 2023)
- Analyse : Vous voulez 1 ligne par entreprise-année avec total annuel
Format Large vs. Long
Format Large
Chaque période de temps est une colonne
| firm_id | Q1_vat | Q2_vat | Q3_vat | Q4_vat |
|---|---|---|---|---|
| FIRM_01 | 1000 | 1200 | 1100 | 1300 |
| FIRM_02 | 800 | 900 | 950 | 1000 |
Bon pour :
- Calculer les changements période-à-période
- Tableaux récapitulatifs
- Visualisation style feuille de calcul
Format Long
Chaque observation est une ligne
| firm_id | quarter | vat_amount |
|---|---|---|
| FIRM_01 | Q1 | 1000 |
| FIRM_01 | Q2 | 1200 |
| FIRM_01 | Q3 | 1100 |
| FIRM_01 | Q4 | 1300 |
| FIRM_02 | Q1 | 800 |
Bon pour :
- Graphiques de séries temporelles
- Opérations group-by
- La plupart des analyses statistiques
Partie 2 : Transformer les Données
Pourquoi Pivot Longer ?
Transformation la plus courante dans l’analyse de données fiscales
Données de TVA trimestrielles larges :
| firm_id | vat_q1 | vat_q2 | vat_q3 | vat_q4 |
|---|---|---|---|---|
| FIRM_01 | 5000 | 5200 | 4800 | 5500 |
↓ Transformer en long ↓
| firm_id | quarter | vat_amount |
|---|---|---|
| FIRM_01 | Q1 | 5000 |
| FIRM_01 | Q2 | 5200 |
| FIRM_01 | Q3 | 4800 |
| FIRM_01 | Q4 | 5500 |
Pourquoi ? Requis pour :
- Tracer les tendances temporelles avec ggplot2
- Calculer les taux de croissance trimestriels
- Opérations group-by (ex., moyenne par trimestre)
- Toute analyse traitant le temps comme variable
Syntaxe de pivot_longer()
Décomposition :
cols: Colonnes à transformer (celles avec des mesures répétées)names_to: Nom de la nouvelle colonne qui contiendra les noms d’anciennes colonnesvalues_to: Nom de la nouvelle colonne qui contiendra les valeurs
Pensez-y comme “déballer”
Vous prenez des colonnes (Q1, Q2, Q3, Q4) et les déballez en lignes, stockant le nom de colonne (Q1) et sa valeur (5000) séparément.
Exemple en Direct : Pivot Longer
# Montrer d'abord le format large
head(vat_wide, 3)
# Transformer en format long
vat_long <- vat_wide %>%
pivot_longer(
cols = c(vat_q1, vat_q2, vat_q3, vat_q4),
names_to = "quarter",
values_to = "vat_amount"
)
# Montrer le résultat
head(vat_long, 6)
# Vérifier les dimensions
cat("Format large:", nrow(vat_wide), "lignes\n")
cat("Format long:", nrow(vat_long), "lignes (4x plus !)\n")🏋️♀️ Exercice 1 : Pratique de Pivot Longer
Tâche : Transformer les données d’impôt sur les sociétés larges fournies en format long
- Ouvrez
exercise_04_01_template.R - Chargez les données CIT larges depuis
data/Intermediate/cit_wide.csv - Utilisez
pivot_longer()pour transformer les colonnes d’année en format long - Vérifiez que le résultat a 4x plus de lignes
10:00 Pourquoi Pivot Wider ?
Moins courant, mais important pour des tâches spécifiques
Données en format long :
| firm_id | year | tax_type | amount |
|---|---|---|---|
| FIRM_01 | 2023 | VAT | 20000 |
| FIRM_01 | 2023 | CIT | 15000 |
| FIRM_02 | 2023 | VAT | 18000 |
| FIRM_02 | 2023 | CIT | 12000 |
↓ Transformer en large ↓
| firm_id | year | VAT | CIT |
|---|---|---|---|
| FIRM_01 | 2023 | 20000 | 15000 |
| FIRM_02 | 2023 | 18000 | 12000 |
Pourquoi ? Utile pour :
- Créer des tableaux récapitulatifs
- Calculer des ratios (TVA/CIT)
- Comparaisons période-à-période
- Comparaisons côte à côte
Syntaxe de pivot_wider()
Décomposition :
id_cols: Colonnes qui identifient uniquement chaque ligne dans le résultatnames_from: Quelle colonne contient les valeurs qui deviendront de nouveaux noms de colonnevalues_from: Quelle colonne contient les valeurs pour remplir les nouvelles colonnes
Attention aux doublons !
Si vous avez plusieurs lignes avec la même combinaison de id_cols et names_from, pivot_wider() créera une colonne de liste. Vérifiez toujours vos données d’abord !
Exemple en Direct : Pivot Wider
# Créer des données d'exemple avec TVA et CIT
tax_long <- tibble(
firm_id = rep(c("FIRM_01", "FIRM_02"), each = 2),
year = rep(2023, 4),
tax_type = rep(c("VAT", "CIT"), 2),
amount = c(20000, 15000, 18000, 12000)
)
# Montrer le format long
print(tax_long)
# Transformer en format large
tax_wide <- tax_long %>%
pivot_wider(
id_cols = c(firm_id, year),
names_from = tax_type,
values_from = amount
)
# Montrer le résultat
print(tax_wide)
# Maintenant nous pouvons facilement calculer le ratio TVA/CIT
tax_wide <- tax_wide %>%
mutate(vat_cit_ratio = VAT / CIT)
print(tax_wide)Partie 3 : Joindre les Données
Pourquoi Joindre les Données ?
Dans l’administration fiscale, les données vivent dans des systèmes séparés :
Système TVA
- Déclarations trimestrielles
- TVA input/output
- Remboursements
Système Impôt Sociétés
- Déclarations annuelles
- Revenu imposable
- Impôt payé
Registre Entreprises
- Industrie
- Taille
- Région
L’Objectif
Combiner ces jeux de données pour analyser le comportement des entreprises à travers plusieurs types d’impôts et caractéristiques.
Le Modèle de Données Relationnel
Trois tables séparées liées par firm_id :
Table 1 : TVA (panel_vat)
| firm_id | quarter | vat_amount |
|---|---|---|
| FIRM_01 | Q1 | 5000 |
| FIRM_01 | Q2 | 5200 |
Table 2 : Impôt Sociétés (panel_cit)
| firm_id | year | cit_amount |
|---|---|---|
| FIRM_01 | 2023 | 15000 |
| FIRM_02 | 2023 | 12000 |
Table 3 : Entreprises (dt_firms)
| firm_id | industry | size |
|---|---|---|
| FIRM_01 | Retail | Medium |
| FIRM_02 | Services | Small |
La clé : firm_id apparaît dans les trois tables, nous permettant de les lier.
Clés de Jointure : Comment R Associe les Lignes
Clé de jointure = La ou les colonnes utilisées pour associer les lignes entre tables
Table A (TVA)
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Table B (Entreprises)
| firm_id | industry |
|---|---|
| FIRM_01 | Retail |
| FIRM_02 | Services |
+
= ?
R associe les lignes où firm_id est identique
- FIRM_01 → Correspond ✓
- FIRM_02 → Correspond ✓
- FIRM_03 → Ne correspond pas ?
Qu’arrive-t-il à FIRM_03 ?
Cela dépend du type de jointure !
Types de Jointures
left_join() : Le Cheval de Bataille
Jointure la plus utilisée (80% des cas réels)
Garde toutes les lignes de la table gauche
Table A (gauche)
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Table B (droite)
| firm_id | industry |
|---|---|
| FIRM_01 | Retail |
| FIRM_02 | Services |
Résultat : left_join(A, B)
| firm_id | vat | industry |
|---|---|---|
| FIRM_01 | 5000 | Retail |
| FIRM_02 | 4500 | Services |
| FIRM_03 | 6000 | NA |
Note : FIRM_03 est conservée, mais industry est NA
Pourquoi c’est la valeur par défaut
Préserve votre jeu de données principal (la table gauche). Parfait pour enrichir des données existantes avec des attributs supplémentaires.
left_join() en Action
# Créer des données d'exemple
vat_data <- tibble(
firm_id = c("FIRM_01", "FIRM_02", "FIRM_03"),
quarter = c("Q1", "Q1", "Q1"),
vat_amount = c(5000, 4500, 6000)
)
firm_data <- tibble(
firm_id = c("FIRM_01", "FIRM_02"),
industry = c("Retail", "Services"),
size = c("Medium", "Small")
)
# Montrer les tables originales
cat("Données de TVA :\n")
print(vat_data)
cat("\nDonnées d'entreprise :\n")
print(firm_data)
# Effectuer left join
vat_enriched <- left_join(vat_data, firm_data, by = "firm_id")
cat("\nAprès left_join :\n")
print(vat_enriched)
# Vérifier le comptage des lignes
cat("\nVérification du comptage des lignes :\n")
cat("Données de TVA :", nrow(vat_data), "lignes\n")
cat("Résultat :", nrow(vat_enriched), "lignes (identique !)\n")🏋️♀️ Exercice 2 : Votre Première Jointure
Tâche : Joindre les données CIT avec les caractéristiques d’entreprise
- Ouvrez
exercise_04_02_template.R - Chargez
panel_cit.csvetdt_firms.csv - Utilisez
left_join()pour ajouter les caractéristiques d’entreprise aux données CIT - Vérifiez que le comptage des lignes correspond aux données CIT
10:00 inner_join() : Seulement les Correspondances
Garde seulement les lignes qui existent dans les DEUX tables
Table A
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Table B
| firm_id | industry |
|---|---|
| FIRM_01 | Retail |
| FIRM_02 | Services |
Résultat : inner_join(A, B)
| firm_id | vat | industry |
|---|---|---|
| FIRM_01 | 5000 | Retail |
| FIRM_02 | 4500 | Services |
Note : FIRM_03 supprimée (pas de correspondance dans Table B)
full_join() : Tout
Garde TOUTES les lignes des DEUX tables
Table A
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
Table B
| firm_id | cit |
|---|---|
| FIRM_02 | 12000 |
| FIRM_03 | 15000 |
Résultat : full_join(A, B)
| firm_id | vat | cit |
|---|---|---|
| FIRM_01 | 5000 | NA |
| FIRM_02 | 4500 | 12000 |
| FIRM_03 | NA | 15000 |
Note : Toutes les entreprises conservées, avec NAs où il n’y a pas de correspondance
anti_join() : L’Outil de Détective
Retourne les lignes de la table gauche qui N’ont PAS de correspondance dans la table droite
Table A (Déclarants TVA)
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Table B (Déclarants CIT)
| firm_id | cit |
|---|---|
| FIRM_01 | 15000 |
| FIRM_02 | 12000 |
Résultat : anti_join(A, B)
| firm_id | vat |
|---|---|
| FIRM_03 | 6000 |
Note : Seulement FIRM_03 retournée (a déposé TVA mais pas CIT)
Critique pour les diagnostics !
Utilisez anti_join() pour trouver :
- Entreprises qui ont déposé TVA mais pas CIT
- Enregistrements qui ne se sont pas joints (problèmes de qualité de données)
- Valeurs manquantes dans les tables de référence
Comparaison Visuelle : Les Quatre Types de Jointure
Mêmes Données d’Exemple, Différents Types de Jointure :
Table A (TVA)
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Table B (CIT)
| firm_id | cit |
|---|---|
| FIRM_01 | 15000 |
| FIRM_02 | 12000 |
| FIRM_04 | 18000 |
Comparaison Visuelle : Résultats
left_join(A, B)
| firm_id | vat | cit |
|---|---|---|
| FIRM_01 | 5000 | 15000 |
| FIRM_02 | 4500 | 12000 |
| FIRM_03 | 6000 | NA |
Lignes : 3 (toutes de A)
inner_join(A, B)
| firm_id | vat | cit |
|---|---|---|
| FIRM_01 | 5000 | 15000 |
| FIRM_02 | 4500 | 12000 |
Lignes : 2 (seulement correspondances)
full_join(A, B)
| firm_id | vat | cit |
|---|---|---|
| FIRM_01 | 5000 | 15000 |
| FIRM_02 | 4500 | 12000 |
| FIRM_03 | 6000 | NA |
| FIRM_04 | NA | 18000 |
Lignes : 4 (toutes des deux)
anti_join(A, B)
| firm_id | vat |
|---|---|
| FIRM_03 | 6000 |
Lignes : 1 (dans A, pas dans B)
Meilleures Pratiques de Jointure
Jointures avec Clés Multiples
Parfois une clé ne suffit pas
Problème : La même entreprise apparaît dans plusieurs années
Données TVA (panel)
| firm_id | year | quarter | vat |
|---|---|---|---|
| FIRM_01 | 2022 | Q1 | 5000 |
| FIRM_01 | 2023 | Q1 | 5200 |
Caractéristiques entreprise (aussi panel)
| firm_id | year | industry |
|---|---|---|
| FIRM_01 | 2022 | Retail |
| FIRM_01 | 2023 | Retail |
Si vous joignez seulement par firm_id, vous obtiendrez des correspondances en double !
Noms de Colonnes Différents
Les données réelles ont souvent une nomenclature incohérente
Table A utilise ‘id’
| id | vat |
|---|---|
| FIRM_01 | 5000 |
Table B utilise ‘firm_id’
| firm_id | industry |
|---|---|
| FIRM_01 | Retail |
Partie 4 : Valider les Jointures
Pourquoi la Validation Importe
⚠️ Histoire d’Horreur
Vous exécutez une jointure. Tout semble bien. Vous envoyez les résultats à votre directeur.
😱 Le lendemain :
“Ces chiffres semblent incorrects. Pourquoi avons-nous 50 000 observations entreprise-année quand nous n’avons que 5 000 entreprises ?”
Que s’est-il passé ? Clés dupliquées dans la table droite ont causé une explosion de lignes.
Leçon : Faites confiance, mais vérifiez. Validez TOUJOURS vos jointures.
Problèmes Courants de Jointure
- Clés dupliquées → Explosion de lignes
- La table droite a plusieurs lignes par clé
- Résultat : Plus de lignes que vous n’avez commencé
- Clés manquantes → NAs non désirés
- Les clés ne correspondent pas entre tables
- Résultat : Beaucoup de valeurs manquantes
- Désaccords de types de données → Zéro correspondance
- Une table a des IDs numériques, l’autre a des IDs caractères
- Résultat : Aucune ligne ne correspond
- Erreurs typographiques dans les noms de colonnes de jointure
- Vous avez écrit
by = "firm_id"mais une table utilise"firm_ID" - Résultat : Erreur ou jointure cartésienne
- Vous avez écrit
Liste de Contrôle Diagnostique
AVANT de joindre :
# 1. Vérifier les clés dupliquées dans les deux tables
panel_vat %>%
count(firm_id, year) %>%
filter(n > 1)
dt_firms %>%
count(firm_id, year) %>%
filter(n > 1)
# 2. Vérifier que les colonnes clés existent et ont le même type
str(panel_vat$firm_id)
str(dt_firms$firm_id)
# 3. Vérifier les valeurs manquantes dans les colonnes clés
sum(is.na(panel_vat$firm_id))
sum(is.na(dt_firms$firm_id))Liste de Contrôle Diagnostique (suite)
APRÈS avoir joint :
# 4. Vérifier le comptage des lignes - a-t-il un sens ?
cat("Avant de joindre :", nrow(panel_vat), "lignes\n")
cat("Après avoir joint :", nrow(merged_data), "lignes\n")
# Pour left_join, devrait correspondre à la table gauche (sauf si droite a des doublons)
# Pour inner_join, devrait être inférieur ou égal à l'une ou l'autre table
# 5. Trouver les non-correspondances en utilisant anti_join
unmatched <- anti_join(panel_vat, dt_firms, by = c("firm_id", "year"))
cat("Lignes sans correspondance :", nrow(unmatched), "\n")
# 6. Vérifier les NAs inattendus dans les colonnes jointes
merged_data %>%
summarize(
na_industry = sum(is.na(industry)),
na_size = sum(is.na(size))
)
# 7. Vérification ponctuelle de quelques lignes
merged_data %>%
filter(firm_id == "FIRM_001") %>%
select(firm_id, year, vat_amount, industry, size)🏋️♀️ Exercice 3 : Diagnostiquer et Réparer
Tâche : La jointure fournie produit le mauvais nombre de lignes. Trouvez et réparez le problème.
- Ouvrez
exercise_04_03_template.R - Exécutez le code de jointure cassé
- Utilisez les outils de diagnostic pour identifier le problème
- Réparez la jointure et validez le résultat
15:00 Partie 5 : Flux de Travail Complet
Assembler le Tout
Scénario Réaliste : Calculer l’Écart de TVA par Taille d’Entreprise
Votre directeur veut identifier les 5 principales entreprises avec les plus grands écarts de TVA dans le commerce de détail, segmentées par taille.
Le Pipeline :
- Transformer : Convertir les données de TVA trimestrielles du format large au format long
- Agréger : Calculer les totaux annuels de TVA par entreprise
- Agréger : Calculer le revenu imposable annuel des données CIT
- Joindre : Combiner TVA avec données CIT pour obtenir le revenu imposable
- Joindre : Ajouter les caractéristiques d’entreprise (industrie)
- Catégoriser : Créer des catégories de taille d’entreprise basées sur le revenu imposable
- Petite : Revenu Imposable < 50K$
- Moyenne : 50K$ ≤ Revenu Imposable < 125K$
- Grande : Revenu Imposable ≥ 125K$
- Calculer : Écart TVA = TVA Attendue - TVA Réelle Payée
- Filtrer et Classer : Sélectionner l’industrie du commerce de détail, trouver le top 5 par catégorie de taille
- Valider : Vérifier que les résultats ont du sens
Codage en Direct : Pipeline Complet
# Étape 1 : Transformer TVA de large à long (si nécessaire)
# Dans cet exemple, panel_vat est déjà en format long, donc nous agrégeons directement
# Étape 2 : Agréger TVA au niveau entreprise-année
vat_annual <- panel_vat %>%
mutate(year = lubridate::year(declaration_date)) %>%
group_by(firm_id, year) %>%
summarize(
actual_vat = sum(vat_outputs - vat_inputs, na.rm = TRUE),
vat_inputs = sum(vat_inputs, na.rm = TRUE),
vat_outputs = sum(vat_outputs, na.rm = TRUE),
quarters_filed = n(),
.groups = "drop"
)
# Étape 3 : Agréger CIT pour obtenir le revenu imposable
cit_annual <- panel_cit %>%
mutate(year = lubridate::year(declaration_date)) %>%
group_by(firm_id, year) %>%
summarize(
taxable_income = sum(taxable_income, na.rm = TRUE),
.groups = "drop"
)
# Étape 4 : Joindre TVA avec données CIT
vat_cit <- left_join(
vat_annual,
cit_annual,
by = c("firm_id", "year")
)
# Étape 5 : Joindre avec caractéristiques d'entreprise
vat_with_firms <- left_join(
vat_cit,
dt_firms,
by = c("firm_id", "year")
)
# Étape 6 : Créer des catégories de taille basées sur le revenu imposable
vat_with_firms <- vat_with_firms %>%
mutate(
firm_size = case_when(
taxable_income < 50000 ~ "Petite",
taxable_income >= 50000 & taxable_income < 125000 ~ "Moyenne",
taxable_income >= 125000 ~ "Grande",
is.na(taxable_income) ~ "Inconnu",
TRUE ~ "Inconnu"
)
)
# Étape 7 : Calculer l'écart de TVA (exemple simplifié)
# Écart TVA = TVA Attendue - TVA Réelle
vat_analysis <- vat_with_firms %>%
mutate(
expected_vat = vat_outputs * 0.15, # Supposant un taux de TVA de 15%
vat_gap = expected_vat - actual_vat
)
# Étape 8 : Filtrer sur commerce de détail et trouver le top 5 par taille
top_gaps <- vat_analysis %>%
filter(industry == "Retail", !is.na(vat_gap)) %>%
group_by(firm_size) %>%
slice_max(order_by = vat_gap, n = 5) %>%
ungroup()
# Étape 9 : Valider
cat("Résumé de l'analyse :\n")
cat("Total entreprises analysées :", nrow(vat_analysis), "\n")
cat("Entreprises commerce de détail :", sum(vat_analysis$industry == "Retail", na.rm = TRUE), "\n")
cat("Écarts principaux par taille :\n")
print(top_gaps %>% count(firm_size))
# Sauvegarder les résultats
fwrite(
vat_analysis,
here("data", "final", "vat_gap_analysis.csv")
)
cat("\n✓ Analyse d'écart de TVA complète !\n")🏋️♀️ EXERCICE FINAL : Analyse d’Écart de TVA
Tâche : Identifier les 5 principales entreprises du commerce de détail avec les plus grands écarts de TVA, par catégorie de taille
- Ouvrez
exercise_04_final_template.R - Suivez les étapes structurées pour :
- Transformer les données TVA larges en format long
- Calculer les totaux annuels de TVA par entreprise
- Créer des catégories de taille basées sur le revenu imposable
- Joindre les données TVA avec les caractéristiques d’entreprise
- Calculer l’écart de TVA pour chaque entreprise
- Filtrer sur l’industrie du commerce de détail
- Trouver les 5 principales entreprises par catégorie de taille
- Sauvegarder les résultats dans
data/Final/vat_gap_analysis.csv
Cette analyse aidera à identifier les risques de conformité par taille d’entreprise !
20:00 Résumé
Points Clés à Retenir
- Les données tidy suivent trois principes
- Chaque variable est une colonne
- Chaque observation est une ligne
- Chaque valeur est une cellule
- Utilisez
pivot_longer()pour la plupart des tâches de transformation- Large à long est la transformation la plus courante
- Utilisez
left_join()comme votre jointure par défaut- Préserve votre jeu de données principal
- Plus courant dans la pratique (80% des cas)
- Validez toujours vos jointures avant de procéder
- Vérifiez les comptages de lignes
- Recherchez les NAs inattendus
- Utilisez
anti_join()pour trouver les non-correspondances
- Suivez un flux de travail diagnostique :
- Vérifier les clés → Joindre → Vérifier → Analyser
Ressources
📖 Lectures Supplémentaires
R4DS Chapitre 6 : Données tidy
https://r4ds.hadley.nz/data-tidyR4DS Chapitre 20 : Jointures
https://r4ds.hadley.nz/joinsFiche aide-mémoire dplyr : Référence des fonctions de jointure
Fiche aide-mémoire tidyr : Référence des fonctions pivot
Excellent Travail !
🥳 Vous pouvez maintenant :
- Comprendre et appliquer les principes des données tidy
- Transformer les données entre formats large et long
- Combiner plusieurs jeux de données en utilisant les jointures
- Valider vos jointures pour détecter les problèmes
- Construire des jeux de données prêts pour l’analyse
Vous avez résolu le défi !
Vous savez maintenant comment : - Transformer les données trimestrielles en annuelles - Joindre les caractéristiques d’entreprise - Calculer des métriques comme l’écart de TVA - Segmenter par catégories (taille d’entreprise, industrie) - Classer et identifier les principales performances/risques
La pratique rend parfait
La meilleure façon de maîtriser les jointures est de pratiquer avec des données réelles. N’hésitez pas à expérimenter avec différents types de jointures et voir ce qui se passe !